2022.06.20.
AWS에서 분석 플랫폼 구축 실습 Part 4
(PySpark 실습과 오류 해결)
Learning Objectives (학습 목표)
- Glue Dev Endpoints와 SageMaker Notebook을 사용하여 interactively(대화식으로) Glue ETL script를 author(작성)하는 방법 이해
- Boto3를 사용해 Glue API를 call(호출)하여 Glue를 administrative(관리) 및 operational(운영) 활동 수행
Import Libraries
- 사용할 class 중에서 중요한 것들만 소개함.
- SparkContext: Spark functionality(기능)의 주요 entry point. SparkContext는 Spark cluster에 대한 connection을 나타내며, 해당 cluster에 RDD, accumulator, broadcast variable을 만드는 데 사용할 수 있음.
< Spark에서의 RDD: Resillient Distributed Data. 즉, 변하지 않는 분산 데이터. Spark의 가장 기본적인 data 구조로, Spark의 모든 작업은 새로운 RDD를 만들거나 존재하는 RDD를 변형/연산하는 것임. >
< Spark에서의 Accumulator: 번역하면 누적기. 연관 연산을 통해서만 추가되는 variable. 따라서 효율적으로 병렬 지원이 됨. 이들은 sum이나 MapReduce에서와 같이 counter를 구현하는 데 사용될 수 있음. Spark는 기본적으로 숫자 type의 accumulator를 지원하며 programmer는 새로운 type을 추가해 지원할 수 있음. >
- GlueContext: SparkSQL SQLContext object를 wrap하여, Spark platform과 interact하기 위한 mechanism을 provide함.
- boto3: AWS의 Python SDK. 이 library를 사용하여 AWS API를 call함.
- awsglue: 필요한 기능을 provide하는 AWS의 PySpark library
우리가 수행할 Data를 Transform
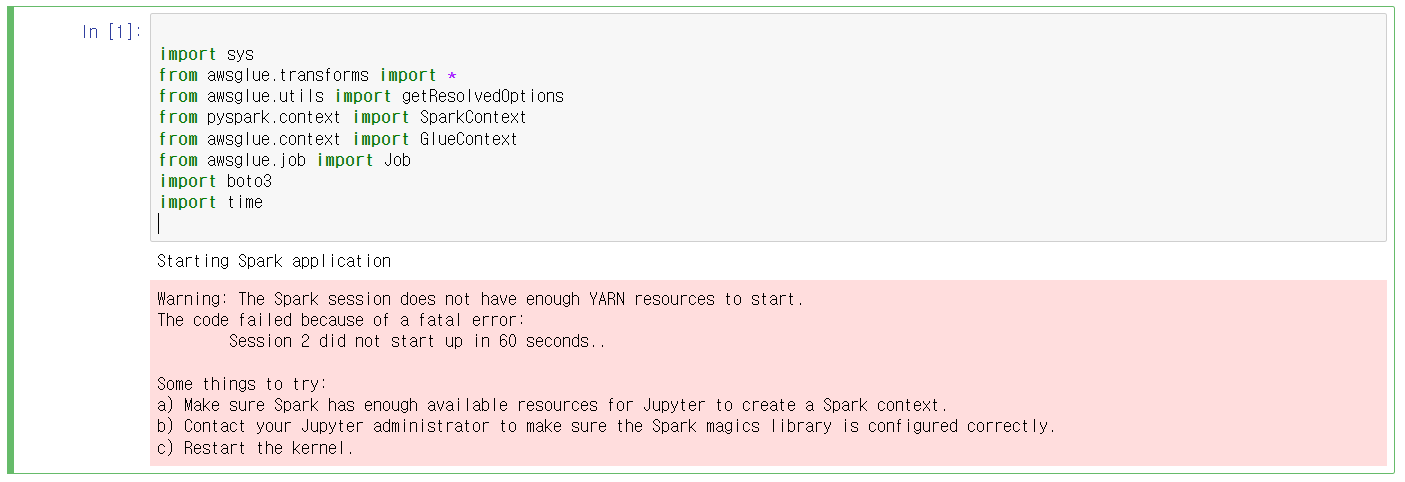
처음 code를 실행하니 다음과 같은 error가 떴다.
Warning: The Spark session does not have enough YARN resources to start.
The code failed because of a fatal error:
Session 2 did not start up in 60 seconds..
Some things to try:
a) Make sure Spark has enough available resources for Jupyter to create a Spark context.
b) Contact your Jupyter administrator to make sure the Spark magics library is configured correctly.
c) Restart the kernel.
해석하면 다음과 같다.
경고: Spark session에 YARN resource가 부족하여 시작할 수 없습니다.
치명적인 error로 인해 code가 실패했습니다.
Session 2가 60초 내에 시작되지 않았습니다.
몇 가지 시도해 볼 사항:
a) Jupyter가 Spark Context를 만들 수 있을 만큼 Spark가 충분한 resource를 가지고 있는지 확인하십시오.
b) Jupyter 관리자에게 문의하여 Spark magic library가 올바르게 구성되었는지 확인하십시오.
c) kernel을 다시 시작합니다.
관련 error를 구글링 해보니 AWS Documentation에 error에 대한 설명이 나와있었다.
Advanced Configuration: Sharing Development Endpoints among Multiple Users - AWS Glue (amazon.com)
Advanced Configuration: Sharing Development Endpoints among Multiple Users - AWS Glue
Please note, development endpoints are intended to emulate the AWS Glue ETL environment as a single-tenant environment. While multi-tenant use is possible, it is an advanced use-case and it is recommended most users maintain a pattern of single-tenancy for
docs.aws.amazon.com

Documentation을 읽어봤지만 Livy Session이 뭔지는 모르겠고,
친절하게 solution으로 a, b, c를 주었으니
일단 내가 할 수 있는 가장 간단한 것인 'c) kernel을 다시 시작합니다.'를 실행해보았다.

그랬더니 매우 쉽게 해결이 되었다.
같은 문제를 겪고 계신 분이 있으시다면, 일단 시간 좀 지난 뒤에 Kernel을 Shutdown 시킨 뒤에 다시 시도해보시길 바란다.
Raw Dataset을 Explore(탐색)하는 과정
- Glue catalog에서 'raw' table의 dynamic frame을 생성함.
- dataset의 schema를 explore함.
- raw table의 row를 count함.
- data의 sample을 view함.
Glue Dynamic Frame의 기초
- Glue의 dynamic(동적) data frame은 강력한 data structure(구조)임.
- 특히 다양한 type의 column이나 field를 처리할 때, underlying(기본) semi-structured(반구조화된) data의 precise(정확한) representation(표현)을 provide함.
- nesting과 unnesting을 다루는 강력한 primitive(기본 요소)를 제공함.
< nest: 중첩되었다는 뜻임. 하나의 query에 subquery가 이중삼중으로 nest될 수 있음. 그러면 unnest 해야 됨. >
< unnest: 중첩된 상태를 풀어낸다는 뜻임. >
- dynamic record는 self-describing record임. 각 record는 그것의 column과 type을 encode하므로, 모든 record는 dynamic frame의 다른 모든 record와는 다른 schema를 가질 수 있음.
- ETL의 경우, 좀 더 dynamic한 것이 필요했기 때문에, Glue Dynamic DataFrame을 만듦. DDF는 rigid(엄격한) schema를 가져야 하는 requirement(요구 사항)를 relax(완화)하는 DF의 implementation(구현)임. semi-structured data를 위해 design됨.
- record당 schema를 maintain하며, restructure하고 tag하고 modify하는 것이 용이함.
Read More: DynamicFrame Class - AWS Glue (amazon.com)
DynamicFrame Class - AWS Glue
DynamicFrame Class One of the major abstractions in Apache Spark is the SparkSQL DataFrame, which is similar to the DataFrame construct found in R and Pandas. A DataFrame is similar to a table and supports functional-style (map/reduce/filter/etc.) operatio
docs.aws.amazon.com

Glue Catalog에서 Dynamic Frame을 Create
- Glue catalog에서 새로운 dynamici frame을 create하기 위해 Glue context를 사용함.
- Glue에서 dynamic frame을 만드는 다른 방법: create_dynamic_frame_from_rdd, create_dynamic_frame_from_catalog, create_dynamic_frame_from_options
Read More: GlueContext Class - AWS Glue (amazon.com)
GlueContext Class - AWS Glue
Thanks for letting us know this page needs work. We're sorry we let you down. If you've got a moment, please tell us how we can make the documentation better.
docs.aws.amazon.com

Schema를 View
- dynamic frame의 schema를 살펴봄.
- printSchema( ): underlying DataFrame의 schema를 print함.


Record를 Count
- data frame의 record number를 count함.
- count( ):underlying DataFrame의 row number를 return함.

Sample Record를 Show
- to 방법을 사용하여 dataset의 sample data를 show할 수 있음.
- show( ) 방법을 사용하여 frame에 sample record를 display할 수 있음.
- 아래의 code를 통해 DF에서 가장 위에 있는 5개의 record를 확인할 수 있음.


Spark SQL을 사용하여 Data를 Explore
- Glue에서 Spark의 SQL engine을 leverage(활용)하여 data에 대한 SQL query를 run할 수 있음.
- my_dynamic_frame이라는 DynamicFrame이 있는 경우, 다음 snippet을 사용하여 DynamicFrame을 DataFrame으로 convert(변환)하고, SQL query를 issue(실행)한 다음 다시 DynamicFrame으로 convert할 수 있음.
(snippet: 작은 조각이란 뜻임. code snippet은 반복되는 pattern의 code 덩어리를 빠르게 입력할 수 있는 일종의 macro 기능임.)
Spark SQL - Filtering & Counting
- 'activity_type = Running'인 event의 number를 filter하고 count함.

- 'activity_type = Working'인 event의 number를 filter하고 count함.

Glue Transform - Filtering & Counting (activity_type = Running)
- Glue in-built(내장) transform을 사용하여 동일한 operation을 perform(수행)할 것임.
- filter transform을 사용할 것임.
- Filter( ): DynamicFrame에서 record를 select하고 filtered DynamicFrame을 return함.
- record가 T/F 중에 무엇을 return하는지를 determine하는 function과 같은 function을 명시할 수 있음.
- 이 function에서는 'activity_type = Running' 조건을 filter함.
Read More: Filter Class - AWS Glue (amazon.com)
Filter Class - AWS Glue
You can use Python’s dot notation to access many fields in a DynamicRecord. For example, you can access the column_A field in dynamic_record_X as: dynamic_record_X.column_A. However, this technique doesn't work with field names that contain anything besi
docs.aws.amazon.com

Glue Transform - Filtering & Counting (activity_type = Working) (Python Lambda Expression을 사용)
- lambda keyword를 사용하여 small anonymous(익명) function을 create할 수 있음.
- Lambda function은 function object가 required한 모든 곳에서 사용할 수 있음. 그들은 single expression으로 syntactically restricted 됨.
- Example: 이 function은 두 argument의 sum을 return함 => lambda a, b: a+b

Glue Transform - 두 DataFrame을 Join
- 두 DynamicFrame에 대해 equality join을 perform함.
- 이 transform은 다음 argument를 accept함.
- frame1: join을 위한 첫 번째 DynamicFrame
- frame2: join을 위한 두 번째 DynamicFrame
- keys1: 첫 번째 frame에 대해 join할 key
- keys2: 두 번째 frame에 대해 join할 key
- raw_data와 reference_data 두 frame을 'track_id' column에 join함
Read More: Join Class - AWS Glue (amazon.com)
Join Class - AWS Glue
Thanks for letting us know this page needs work. We're sorry we let you down. If you've got a moment, please tell us how we can make the documentation better.
docs.aws.amazon.com

Schema를 View
- dynamic frame의 schema를 view함.
- printSchema( ): underlying DataFrame의 schema를 print함.

joined_data DynamicFrame을 Cleaning up(정리)
- 관심있는 column 외에 partition column이 있음.
- 이것들은 S3에서 yyyy/mm/dd/hh directory structure에 file을 place(배치)하기 위해 firehose에 의해 generate(생성)됨.
- Glue의 in-built DropFields transform을 사용하여 partition column을 drop함.
Glue transform에 대해 Read More: Built-In Transforms - AWS Glue (amazon.com)
Built-In Transforms - AWS Glue
Built-In Transforms AWS Glue provides a set of built-in transforms that you can use to process your data. You can call these transforms from your ETL script. Your data passes from transform to transform in a data structure called a DynamicFrame, which is a
docs.aws.amazon.com

DropFields transform 후에 Schema를 View


S3에 Transformed Data를 Write하기
- Glue의 write_dynamic_frame의 functionality(기능)를 사용하여 S3에 transformed data를 write함.
- transformed data를 다른 directory에 parquet format으로 store할 것임.
- D3 bucket 이름을 'minjoooo-analytics-workshop-bucket'으로 변경함.
Parquet Format인 이유
- Apache Parquet: 빠른 data retrieval(검색)을 위해 optimize(최적화)되고 AWS analytical application에 사용되는 columnar storage format
- columnar storage format은 Athena와 함께 사용하는 데 suitable한 다음의 characteristic을 가지고 있음.
- column에 대한 compression(압축)은, column data type에 대해 compression algorithm을 select하여, S3의 storage space(공간)를 save(절약)하고, query processing 중에 disk space와 I/O를 reduce함.
- Parquet과 ORC의 predicate(술부, 주어를 설명하는 내용) pushdown은, query가 필요한 block만 fetch(가져옴)를 가능하게 하여, query performance를 improve시킴.
- query가 data에서 specific한 column value를 obtain할 때, max/min value와 같은 data block predicate의 statistic을 사용하여, block을 read할지 skip할지 determine함.
- Parquet에서 data를 split(분할)하면, analytic tool이 data를 read하는 것을 multiple reader로 split하게 하고, query processing 중에 parallelism(병렬성)을 increase하게 함.

Boto3를 사용하여 Glue를 Run하고 Automate(자동화)
- Boto: Python용 AWS SDK
- Boto는 Python developer가 AWS service를 create, configure(구성), manage할 수 있게 함. Boto는 사용하기 쉬운 object-oriented(객체 지향) API를 provide하며 AWS service에 대한 low loevel의 access를 provide함.
Glue Catalog에 Transformed Dataset를 Add
- transformed data가 S3에 기록됨 => 이것을 Glue catalog에 add하면, Athena를 사용하여 query할 수 있음
- 이 block은 실행되는 데 60초 정도 걸리므로, execution을 stop하면 안 됨.

Boto를 사용하여 analyticsworkshopdb DB의 Table List를 View
